블로그라면 SEO는 해봐야지
- #Blog
- #Next.js
- #SEO
이 글은 Next.js(App Router) 기준으로 작성되었습니다.
드디어 때가 왔다
이 블로그를 개발하면서 꼭 해보자고 생각했던 것이 있습니다. 바로 SEO입니다.
그동안 CSR 중심의 프로젝트를 주로 진행해와서, SEO를 본격적으로 설정해볼 기회는 많지 않았습니다. 그래서 이번에 블로그를 만들면서, SEO에는 어떤 것들이 있고 역할은 무엇인지, 그리고 Next.js에서 이를 어떻게 적용하는지 정리해보려고 합니다.
SEO는 뭘까?
SEO는 Search Engine Optimization의 줄임말로, 말 그대로 검색 엔진을 위한 최적화를 뜻합니다. 구글이나 네이버 같은 검색 엔진은 웹 사이트를 발견하고(Discovery), 가져가서(Crawling), 색인에 넣고(Indexing), 중복 URL이 있으면 대표 주소를 고르는(Canonicalization) 과정을 거쳐서 검색 결과를 노출합니다.
즉, SEO를 적용한다는 건, 검색 엔진이 이 과정을 수월하게 진행할 수 있도록 필요한 힌트들을 정리해두는 작업이라고 보면 되겠죠. 이를 통해 검색 결과에서 더 상위에 노출되고 더 많은 트래픽을 받을 수 있게 될 겁니다.
On-Page SEO와 Off-Page SEO
SEO는 크게 와 오프 페이지 SEO(Off-Page SEO)로 나눌 수 있습니다. 온 페이지 SEO는 title, metadata, sitemap.xml, robots.txt 등 사이트 내부에서 적용하는 SEO를 말하고, 오프 페이지 SEO는 , 브랜딩, 커뮤니티 확산 등 페이지 외부에서 적용되는 SEO를 말합니다.
이 글에서는 온 페이지 SEO 중 제가 Next.js에서 직접 적용해 본 항목들만 골라 정리해 보겠습니다.
Next.js에서 SEO 적용하기
1. 도메인 정리
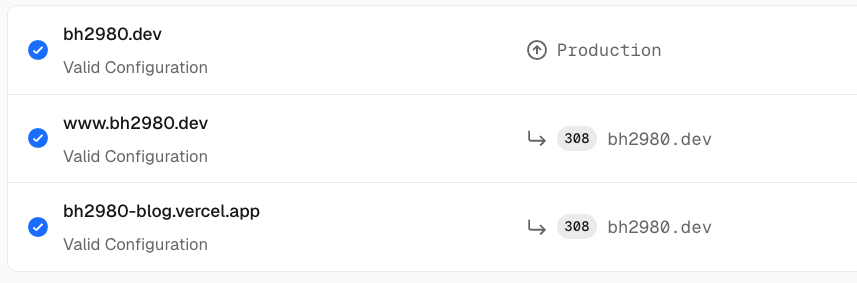
같은 콘텐츠가 여러 도메인에서 열리면, 검색 엔진이 이를 서로 다른 페이지로 인식해서 중복으로 색인하거나, 어느 URL을 대표로 삼을지 혼란이 생길 수 있습니다. 예를 들어 제 블로그는 아래 3개의 도메인으로 접속할 수 있는데요.
이 경우 https://bh2980.dev/posts와 https://bh2980-blog.vercel.app/posts 를 각각 다른 URL로 인식하여 색인하기 때문에 결과가 분산되는 문제가 생깁니다. 이를 방지하기 위해 대표 도메인으로 정하고 나머지는 모두 https://bh2980.dev로 리다이렉트되도록 통일했습니다.
2. metadata
메타데이터는 페이지의 내용을 요약해서 설명하는 데이터입니다. 즉, 본문 내용이 아닌 검색 엔진이나 브라우저가 페이지를 이해하고 표시하는 데 사용되는 부가 정보로, 주로 <head> 태그 안에 들어갑니다.
대표적으로 title 같은 속성이 있는데요. title이 설정될 경우 브라우저의 탭에 타이틀에 들어간 텍스트가 표시되는 것을 볼 수 있습니다.
<head>
<title>bh2980.dev</title>
</head>
그렇다면 Next.js에서는 이를 어떻게 설정할 수 있을까요? 바로 각 페이지나 레이아웃 파일에서 metadata 객체를 사용하거나 generateMetadata 함수를 사용하면 됩니다.
import type { Metadata } from "next";
export const metadata: Metadata = {
title: "블로그",
description: "개발하면서 배운 것들과 경험을 기록합니다.",
};이 둘의 차이는 메타데이터가 정적인지 동적인지의 차이입니다.
저는 글 본문 페이지에 /posts/[slug] 형태의 라우트를 사용하기 때문에 글 본문의 페이지 파일에서 정적으로 메타데이터를 결정할 수 없습니다. 이 경우에 metadata 객체가 아니라 generateMetadata를 사용하면 각 게시글의 정보를 불러와 동적으로 메타데이터를 생성할 수 있습니다.
만약 메타데이터를 설정하지 않은 페이지는 기본적으로 상위 라우트의 메타데이터를 상속받습니다. 그래서 앱 루트 라우트 혹은 레이아웃 파일에서 기본 설정을 해두고, 필요한 라우트에만 다시 설정해주면 편합니다.
export async function generateMetadata(): Promise<Metadata> {
return {
metadataBase: "https://bh2980.dev",
title: "bh2980.dev",
description: "bh2980의 개발 블로그",
};
}여기서 한 가지 특이한 속성이 있는데 바로 metadataBase입니다. 이 속성은 canonical, alternates, openGraph, twitter 등 절대 URL이 필요한 메타데이터에서 상대 경로를 사용할 수 있게 해주는 기준 URL로, /posts 같은 값을 자동으로 https://bh2980.dev/posts 형태의 절대 URL로 변환해줍니다. 설정해두면 편해서 해두는 것을 추천합니다.
3. canonical
<link rel="canonical" href="https://bh2980.dev/posts">캐노니컬(canonical) 태그는 동일하거나 거의 동일한 콘텐츠를 가리키는 여러 URL 중에서 검색 엔진이 대표로 인식해야 할 URL을 지정하는 태그입니다.
예를 들어 제 블로그의 글 목록 페이지는 category 기준으로 필터링할 수 있으며, 이 과정에서 category 쿼리 스트링이 URL에 추가됩니다.
이 둘은 사용자에게는 분명히 다른 페이지이지만, 검색 엔진 입장에서는 동일한 글 목록 페이지의 변형에 불과하므로 색인과 평가는 하나의 URL로 통합하는 편이 합리적입니다. 이럴 때 바로 캐노니컬 태그를 사용합니다.
Next.js에서 캐노니컬의 값은 앞서 작성한 메타데이터의 alternates 속성에서 정의할 수 있습니다.
export const metadata: Metadata = {
title: "블로그",
description: "개발하면서 배운 것들과 경험을 기록합니다.",
alternates: { canonical: `/posts` },
};위와 같이 설정하면 /posts 페이지를 기준으로 <link rel="canonical"> 태그가 자동으로 생성되며, 쿼리 스트링이 붙은 URL들은 검색 엔진 관점에서 모두 /posts의 변형으로 인식되어 색인과 평가 기준이 하나의 URL로 통합됩니다.
4. robots.txt
robots.txt는 검색 엔진 크롤러가 어떤 경로를 크롤링 할 수 있는지 제어하는 역할을 합니다. 사이트의 루트 경로인 /robots.txt에 위치하고, 크롤러는 이 파일을 먼저 확인한 뒤 페이지를 탐색합니다.
예를 들어, 검색 결과에 노출될 필요가 없는 admin 페이지나 API 경로가 존재할 경우, 이를 Disallow에 등록하면 해당 경로는 크롤링 대상에서 제외됩니다. 다만 이는 접근을 아예 차단하는 설정이 아니라, 크롤러에게 해당 경로를 탐색하지 말도록 안내하는 규칙에 가깝습니다.
Disallow: /api/Next.js에서는 src/app 디렉터리에 robots.txt 또는 robots.ts 파일을 추가하면, 빌드 결과로 사이트 루트에 해당 파일이 생성됩니다.
이 역시 메타데이터와 마찬가지로 정적으로 정의할 경우 txt 파일로 정의하면 되고, 동적인 값이 필요한 경우 robots 함수를 활용해 정의 할 수 있습니다.
두 방식 모두 최종적으로 동일한 robots.txt를 생성합니다. 특별히 동적인 값이 필요하지 않다면 정적 파일만으로도 충분하지만, 저는 타입 지원과 일관된 메타데이터 관리 방식을 유지하기 위해 robots 함수를 사용하는 방식을 선택했습니다.
기존의 robots.txt와 별개로 메타데이터에서 작성할 수 있는 robots 속성도 존재합니다. robots.txt가 사이트 전체에 대한 크롤링 정책을 설정한다면, 메타데이터의 robots 속성은 페이지별 색인 여부와 링크 추적 여부를 설정한다는 점에서 다릅니다.
const metadata = {
title: "Not Found",
robots: { index: false, follow: true },
}5. sitemap.xml
robots.txt가 크롤러에게 페이지의 크롤링 정책을 안내하는 역할이라면, sitemap.xml은 사이트 내에서 크롤링 및 색인이 이루어지길 원하는 URL 목록을 검색 엔진에 전달하는 역할을 합니다. 즉, robots.txt와는 상호보완적 관계라고 할 수 있겠죠.
Next.js에서 사이트맵을 작성할 때 이전과 마찬가지로 정적으로 적을 수도, 동적으로 적을 수도 있습니다만, 정적으로 적는 것은 추천하지 않습니다. 사이트맵에 적어야하는 파일이 많고 추가될 때마다 수정해주어야하기 때문에 누락이나 실수할 가능성이 높기 때문입니다.
import type { MetadataRoute } from "next";
import { getPostList } from "@/libs/contents/post";
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const posts = await getPostList();
const postsSitemap = posts.list.map<MetadataRoute.Sitemap[number]>((post) => ({
url: new URL(`https://bh2980.dev/posts/${post.slug}`).toString(),
}));
return [
{
url: 'https://bh2980.dev',
},
{
url: `https://bh2980.dev/posts`,
},
...postsSitemap,
];
}저는 Next.js에서 제공하는 sitemap 함수에 게시글과 메모 리스트를 가져와 넣어주는 방식으로 작성했는데요. URL과 필요한 정보가 있는 배열을 return하면 간편하게 사이트맵을 생성할 수 있습니다.
sitemap 함수를 이용하면 게시글이 추가될 때마다 사이트맵이 함께 갱신되므로, 수동으로 관리할 때 발생할 수 있는 누락 가능성을 줄일 수 있습니다.
하나의 사이트맵에 들어갈 수 있는 URL의 개수는 최대 50,000개입니다. 만약 URL이 매우 많다면, Next.js에서 제공하는 다중 사이트맵 생성 방식을 이용해 사이트맵을 여러 개로 나누어 만들 필요가 있습니다.
이렇게 만든 사이트맵 파일은 사이트의 루트 경로에서 찾아볼 수 있습니다.
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://bh2980.dev</loc>
</url>
<url>
<loc>https://bh2980.dev/posts</loc>
</url>
<url>
<loc>https://bh2980.dev/posts/%EB%B8%94%EB%A1%9C%EA%B7%B8%EB%A5%BC-%EB%8B%A4%EC%8B%9C-%EB%A7%8C%EB%93%A4%EB%A9%B4%EC%84%9C</loc>
<lastmod>2026-01-02T18:42+09:00</lastmod>
</url>
...
</urlset>마지막으로 만든 사이트맵을 robots.txt에 등록해주어 검색 엔진이 사이트맵이 어디있는지 쉽게 찾을 수 있도록 설정해주면 좋습니다.
import type { MetadataRoute } from "next";
export default function robots(): MetadataRoute.Robots {
return {
rules: {
userAgent: "*",
allow: "/",
disallow: ["/keystatic/", "/api/"],
},
sitemap: `https://bh2980.dev/sitemap.xml`,
};
}6. OpenGraph

OpenGraph, 흔히 OG 태그라고 부르는 메타데이터는 링크를 공유할 때 표시되는 미리보기 카드(제목, 설명, 대표 이미지 등)의 내용을 정의합니다. 카카오톡이나 디스코드, X(트위터) 같은 서비스는 페이지의 <head>에 포함된 OpenGraph 정보를 읽어, 링크를 카드 형태로 표시합니다.
OG 태그는 robots.txt나 sitemap.xml처럼 검색 엔진의 크롤링이나 색인을 직접 제어하는 요소는 아니지만, 공유 시점에 어떤 제목과 설명, 이미지를 보여줄지를 결정하기 때문에 클릭률 등 간접적으로 SEO에 기여한다고 볼 수 있습니다.
Next.js에서는 메타데이터의 openGraph 속성을 정의해 OG 정보를 설정할 수 있습니다만, 설정하지 않을 시 기본적으로 메타데이터의 title과 description을 사용하게 되어있습니다. 만약 필요하다면 각 페이지의 메타데이터에 openGraph 속성을 사용해 지정해주면 되겠습니다.
export async function generateMetadata(): Promise<Metadata> {
return {
metadataBase: 'https://bh2980.dev',
title: "bh2980.dev",
description: "bh2980의 개발 블로그",
alternates: {
canonical: "/",
},
openGraph: {
type: "website",
siteName: "bh2980.dev",
locale: "ko_KR",
},
};
}하지만 OpenGraph에는 중요한 항목이 하나 더 남아있습니다. 바로 대표 이미지인데요. 대표 이미지 역시 정적 방식과 동적 방식 중 필요한 방식으로 설정할 수 있습니다.
import { ImageResponse } from "next/og";
import { getPost } from "@/libs/contents/post";
export const size = { width: 1200, height: 630 };
export const contentType = "image/png";
export async function generateImageMetadata({ params }: { params: Promise<{ slug: string }> }) {
const { slug } = await params;
const post = await getPost(slug);
return [
{
id: "post-og",
alt: post?.title || 'bh2980.dev',
contentType,
size,
},
];
}
export default async function Image({ params }: { params: Promise<{ slug: string }> }) {
const { slug } = await params;
const post = await getPost(slug);
return new ImageResponse(
<div style={{ fontSize: 64, display: "flex", width: "100%", height: "100%", alignItems: "center", justifyContent: "center" }}>
{post.title} | bh2980.dev
</div>,
{ ...size }
);
}저는 동적 방식으로 대표 이미지를 설정해주었는데, opengraph-image.tsx 파일을 만들고 Next.js의 Image 함수와 ImageResponse를 사용하면 대표 이미지를 생성할 수 있습니다. 대표 이미지의 메타데이터를 설정하려면, generateImageMetadata 함수를 사용하면 됩니다.
이처럼 대표 이미지를 동적 방식으로 설정할 경우 컴포넌트 코드처럼 작성할 수 있다는 특징이 있습니다. 하지만 모든 CSS 문법을 지원하는 것은 아니므로 스타일이 적용되는지 유의하며 사용해야 합니다.
ImageResponse 내에서 tailwind 문법을 사용하려면 className이 아닌 tw 속성을 사용하면 됩니다. 단, 이 역시 모든 속성이 지원되는 것이 아니므로 유의하여 사용하여야 합니다.
그렇다면 만들어진 OpenGraph는 개발 과정에서는 확인하기 어렵다는 단점이 있는데요. 크롬 확장 프로그램인 Social Share Preview를 활용하면 쉽게 개발 과정에서 OpenGraph 태그가 어떻게 적용될지 확인할 수 있습니다.
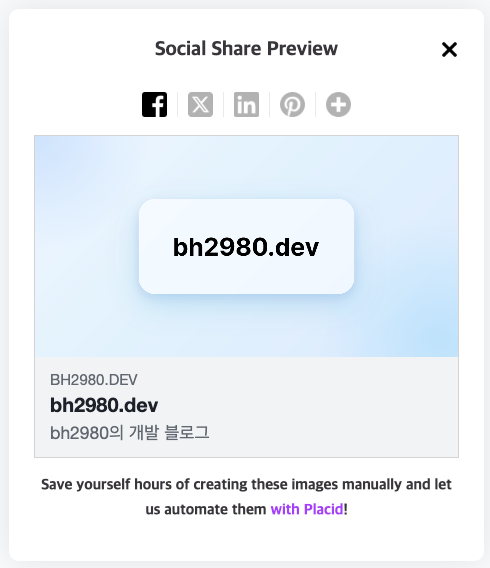
설정된 OpenGraph 정보는 head 태그에 아래처럼 들어가게 됩니다.
<meta property="og:title" content="bh2980.dev">
<meta property="og:description" content="bh2980의 개발 블로그">
<meta property="og:site_name" content="bh2980.dev">
<meta property="og:locale" content="ko_KR">
<meta property="og:image:alt" content="bh2980의 개발 블로그">
<meta property="og:image:type" content="image/png">
<meta property="og:image" content="https://bh2980.dev/opengraph-image?7a929ff6ab76b034">
<meta property="og:image:width" content="1200">
<meta property="og:image:height" content="630">
<meta property="og:type" content="website">twitter 태그 역시 OpenGraph와 동일한 방식으로 적용할 수 있습니다. 만약 twitter 태그를 별도로 지정하지 않을 경우 OpenGraph 속성의 정보를 사용하여 생성됩니다.
7. RSS
RSS는 Really Simple Syndication의 줄임말로, 사이트의 새 글 목록을 XML 형식으로 제공하는 피드입니다. 주로 특정 사이트를 구독하여 새 글이 올라올 때마다 받아보는 용도로 사용됩니다.
RSS는 주로 구독자를 위한 기능이지만, 새 글이 발행되었음을 외부에 알리는 채널로도 활용할 수 있어 함께 제공해두면 좋습니다.
Next.js에서는 RSS를 위한 문법이 별도로 제공되진 않지만, Route Handler를 통해 RSS를 제공하는 방법을 소개하고 있습니다.
import { Feed } from "feed";
import { getPostList } from "@/libs/contents/post";
const SITE_URL = "https://bh2980.dev";
export async function GET() {
const siteUrl = new URL(SITE_URL);
const feedUrl = new URL("/rss.xml", siteUrl).href;
const { list } = await getPostList();
const feed = new Feed({
title: "bh2980.dev",
description: "bh2980의 개발 블로그",
id: siteUrl.href,
link: siteUrl.href,
language: "ko",
feedLinks: { rss2: feedUrl },
updated: new Date(),
});
for (const post of list) {
const url = new URL(`/posts/${post.slug}`, siteUrl).href;
feed.addItem({
title: post.title,
id: url,
link: url,
description: post.excerpt ?? "",
date: new Date(post.publishedDateTimeISO),
});
}
return new Response(feed.rss2(), {
headers: {
"Content-Type": "application/rss+xml; charset=utf-8",
"X-Robots-Tag": "noindex, follow",
},
});
}저는 feed 라이브러리를 사용해서 RSS를 만들어주었습니다. 조금 특이한 건, 응답 헤더에 X-Robots-Tag를 설정해주었는데요. RSS를 색인하지는 않되, 내부의 링크는 따라가길 바라서 위처럼 설정해두었습니다.
이제 홈페이지에서 /rss.xml로 들어가면 RSS가 생성된 것을 볼 수 있습니다.
<?xml version="1.0" encoding="utf-8"?>
<rss version="2.0">
<channel>
<title>bh2980.dev</title>
<link>https://bh2980.dev/</link>
<description>bh2980의 개발 블로그</description>
<lastBuildDate>Fri, 02 Jan 2026 09:42:00 GMT</lastBuildDate>
<docs>https://validator.w3.org/feed/docs/rss2.html</docs>
<generator>https://github.com/jpmonette/feed</generator>
<language>ko</language>
<item>
<title><![CDATA[블로그를 다시 만들면서]]></title>
<link>https://bh2980.dev/posts/%EB%B8%94%EB%A1%9C%EA%B7%B8%EB%A5%BC-%EB%8B%A4%EC%8B%9C-%EB%A7%8C%EB%93%A4%EB%A9%B4%EC%84%9C</link>
<guid isPermaLink="false">https://bh2980.dev/posts/%EB%B8%94%EB%A1%9C%EA%B7%B8%EB%A5%BC-%EB%8B%A4%EC%8B%9C-%EB%A7%8C%EB%93%A4%EB%A9%B4%EC%84%9C</guid>
<pubDate>Fri, 02 Jan 2026 09:42:00 GMT</pubDate>
<description><![CDATA[문득 개발 블로그를 만들어야겠다고 생각했습니다. 사실 옛날부터 어렴풋하게 다짐만 해오던 목표이긴 했습니다만, 이렇게 문득 열정이 생긴 건 연말을 맞아 허무하게 한 해를 끝낼 수 없다는 생각 때문이었을지도 모르겠습니다. 그렇다고 개발 블로그를 운영하지 않았던 것은 또 아닙니다. 개발 블로그는 개발자의 덕목이자 로망 아닐까요? 저 역시도 동일한 생각으로 티스토]]></description>
</item>
</channel>
</rss>이렇게 RSS를 만들어주었다면, 검색 엔진이 이를 찾을 수 있도록 메타데이터에 추가해주는 것이 필요합니다.
export async function generateMetadata(): Promise<Metadata> {
return {
metadataBase: "https://bh2980.dev",
title: "bh2980.dev",
description: "bh2980의 개발 블로그",
alternates: {
canonical: "/",
types: {
"application/rss+xml": "/rss.xml",
},
},
openGraph: {
type: "website",
siteName: "bh2980.dev",
locale: "ko_KR",
},
};
}이렇게 추가하게 되면 head 태그에 RSS에 관한 정보가 아래처럼 들어가게 됩니다.
<link rel="alternate" type="application/rss+xml" href="https://bh2980.dev/rss.xml">8. Google Search Console
Google Search Console(이하 GSC)는 구글이 내 사이트를 어떻게 크롤링하고, 색인하고, 검색 결과에 노출하는지 확인할 수 있게 해주는 도구입니다. GSC 역시 설정을 적용하는 항목이라기 보다는 내가 적용한 SEO 설정들이 제대로 동작하는지 검증하는 용도에 가깝습니다.
GSC를 사용하려면 먼저 사이트 소유권을 확인해야 합니다. 소유권 확인 방법은 여러 가지가 있지만, 저는 가장 간단한 메타 태그 방식을 사용했습니다.
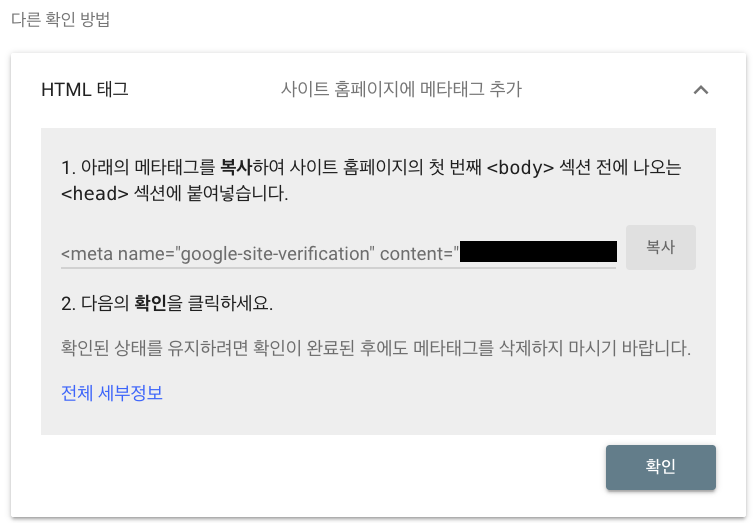
URL을 입력하고 계속을 누르면 메타 태그를 추가하라는 안내가 나옵니다. 이 태그의 값을 복사해서 앱 루트의 메타데이터에 추가하면 소유권 인증 설정이 완료됩니다.
export async function generateMetadata(): Promise<Metadata> {
return {
metadataBase: "https://bh2980.dev",
title: "bh2980.dev",
description: "bh2980의 개발 블로그",
alternates: {
canonical: "/",
types: {
"application/rss+xml": "/rss.xml",
},
},
openGraph: {
type: "website",
siteName: "bh2980.dev",
locale: "ko_KR",
},
verification: {
google: "token 값",
},
};
}이후 사이트에 접속해보면 head 태그에 해당 토큰 값이 추가된 것을 확인할 수 있습니다.
<meta name="google-site-verification" content="token 값">다시 GSC에 접속해보면 소유권 인증이 완료되고 대시보드로 접속되는 것을 확인할 수 있습니다.
소유권 인증이 완료되었다면, 가장 먼저 해줄 일은 사이트맵을 제출하는 것입니다. 구글이 내 사이트의 구조를 빠르게 파악할 수 있도록, sitemap.xml의 위치를 알려주는 과정이라고 보면 됩니다.
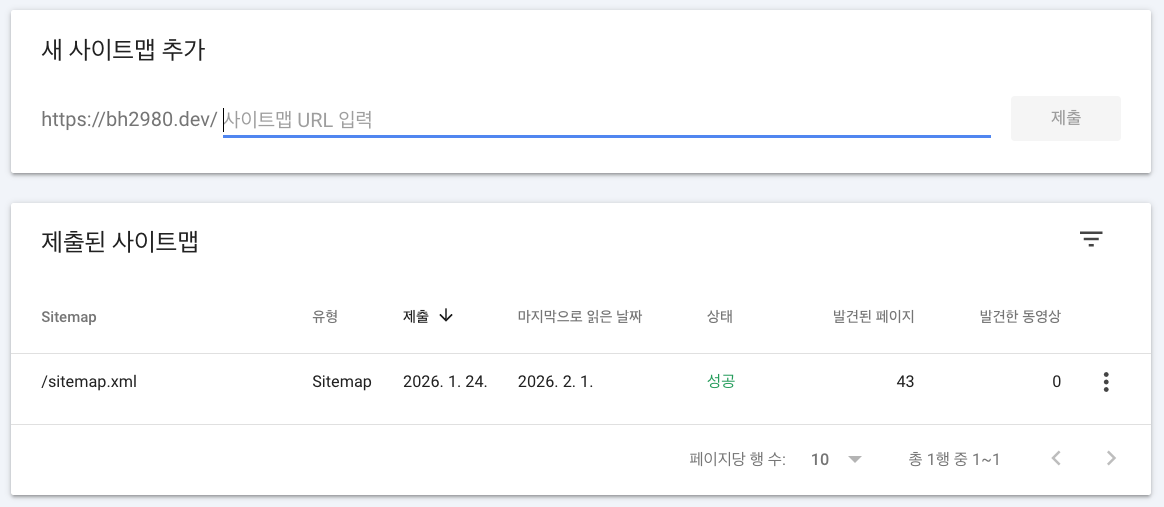
앞에서 sitemap.xml을 생성해두었기 때문에, 이제 GSC에 해당 사이트맵을 등록해주면 됩니다. 이 과정을 통해 구글이 내 사이트의 URL 목록을 보다 안정적으로 수집할 수 있습니다.
사이트맵을 제출한 이후에는, 특정 페이지가 실제로 색인되었는지 확인하거나 개별 URL 상태를 점검하기 위해 URL 검사 도구를 활용할 수 있습니다.
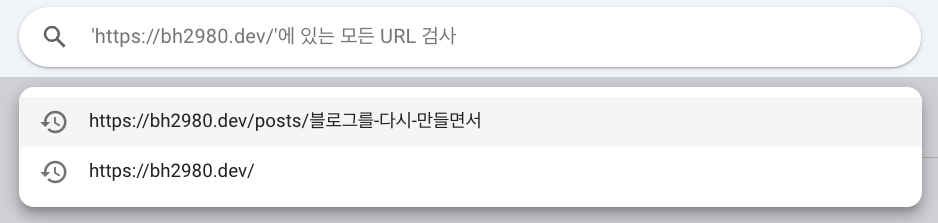
URL 검사는 왼쪽 사이드바에서 URL 검색을 누르거나 검색창에 URL을 입력해서 진행할 수 있습니다. URL 검사 화면에서는 “이 페이지가 실제로 색인되었는지”, “아직 안 됐다면 왜 안 됐는지” 같은 것들을 확인할 수 있습니다.
또한 “실제 URL 테스트”를 통해 현재 페이지가 크롤링 및 색인 가능한 상태인지 점검할 수 있으며, 색인되지 않은 페이지라면 “색인 생성 요청”을 통해 재색인을 요청할 수도 있습니다. 요청 즉시 반영되지는 않지만, 신규 콘텐츠의 반영 속도를 높이는 데 도움이 됩니다.
9. llms.txt
마지막으로 설정해볼 것은 llms.txt입니다. 전통적인 SEO 설정은 아니지만 AI 기반 검색 서비스가 빠르게 성장하고 있는 만큼 고려해볼 만한 설정이라 생각합니다.
llms.txt는 아직 공식 표준으로 확정된 규격은 아니며, AI 모델이나 관련 크롤러가 사이트의 구조와 맥락을 이해할 수 있도록 정보를 정리해두는 용도로 제안된 파일입니다.
기존 robots.txt가 검색 엔진 크롤러를 대상으로 한다면, llms.txt는 LLM 관련 크롤러를 대상으로 한다는 점에서 차이가 있습니다. 다만 강제성이 없기 때문에 모든 LLM이 준수하는 것은 아닙니다.
llms.txt는 마크다운 문법을 따르고, 관례적 구조는 아래와 같습니다.
# 사이트 이름
> 사이트를 한 줄로 요약한 설명
## 섹션 제목
- [리소스 이름](https://example.com/resource)
- [다른 리소스](https://example.com/another)이를 바탕으로 제 블로그의 구조와 주요 리소스를 정리한 llms.txt 파일을 아래와 같이 작성했습니다.
# bh2980.dev
> A personal Korean developer blog by bh2980.
Posts: long-form development notes.
Memos: short notes (problem solving, troubleshooting, snippets, course summaries).
## Sections
- [Posts](https://bh2980.dev/posts): Long-form development notes
- [Memos](https://bh2980.dev/memos): Short notes (problems, troubleshooting, snippets, course summaries)
## Feeds
- [RSS (Posts)](https://bh2980.dev/rss.xml)
## Index
- [Sitemap](https://bh2980.dev/sitemap.xml)
## Notes
- Canonical host: https://bh2980.dev마무리 - SEO는 힘들구나
후, 이렇게 길었던 SEO 작업이 끝났습니다. 그동안 페이지 개발에만 치중해왔는데, 결국 내가 개발한 페이지가 누군가에게 닿기 위해서는 이런 설정들이 필요하다는 것을 알게 되는 시간이었습니다.
당장 눈에 띄는 변화가 나타나지는 않겠지만, 이런 기본 설정들이 쌓여서 장기적으로는 검색 노출과 트래픽에 영향을 줄 것이라 기대해봅니다.
이번 글이 Next.js에서 SEO를 적용해보려는 분들께 작은 참고가 되었으면 좋겠습니다.